Uniqueness
Uniquenessとは
Section titled “Uniquenessとは”Uniquenessは、項目の値がレコード間で一意であるかを測定します。高いUniquenessは各レコードがその項目で異なる値を持つことを意味し、低いUniquenessは重複があることを示します。
各項目に対して、Uniquenessストラテジーは以下を実行します:
- スコープ内のレコードからすべてのnullでない値を収集
- 重複値を識別
- 計算:
(一意の値 / 入力済みの値の合計) × 100
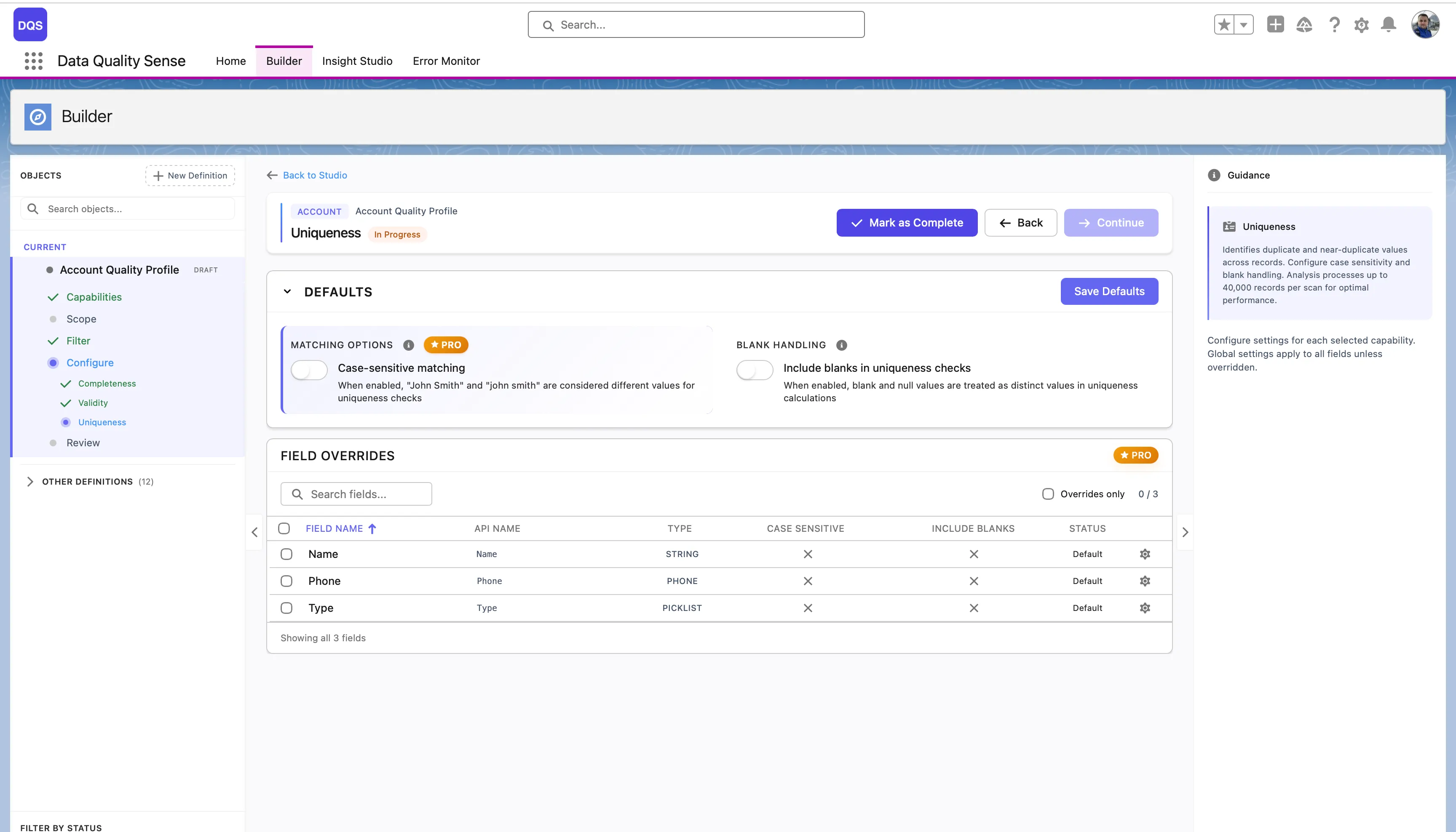
グローバル設定
Section titled “グローバル設定”Defaultsセクションでは、グローバルなUniquenessオプションを制御します:
| 設定 | 説明 |
|---|---|
| 大文字・小文字を区別するマッチング | 有効にすると、「John Smith」と「john smith」は比較時に異なる値とみなされます。無効にすると、重複としてカウントされます。 |
| 空白をUniquenessチェックに含める | 有効にすると、空白やnull値は比較計算で個別の値として扱われます。 |
下部のField Overridesテーブルには、各項目の現在のCase Sensitive、Include Blanks設定、およびステータスがリストされます。
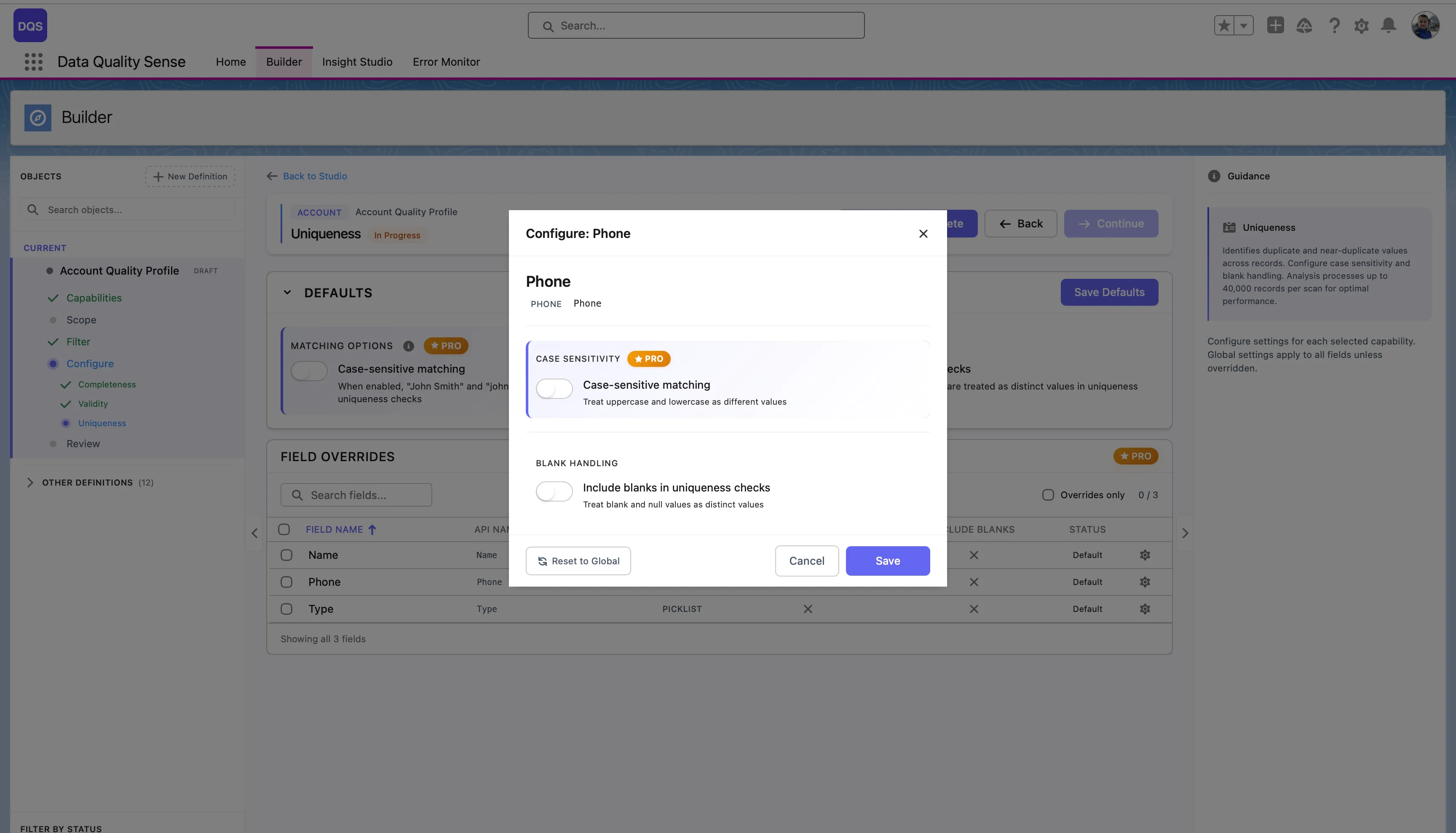
項目ごとのオーバーライド
Section titled “項目ごとのオーバーライド”Field Overridesテーブルで項目をクリックすると、構成モーダルが開きます。グローバルデフォルトとは独立して大文字・小文字を区別するマッチングと空白をUniquenessチェックに含めるを切り替えることができます。Revert to Globalリンクを使用して項目をグローバル設定にリセットできます。
スコアリング
Section titled “スコアリング”| 結果 | スコア |
|---|---|
| すべての値が一意 | 100 |
| 一部に重複あり | 一意の割合に比例 |
| すべての値が同一 | 0に近い |
| データなし | 0 |
Uniqueness分析はスキャンあたり最大40,000レコードを処理します。レコード数がそれ以上のオブジェクトの場合、結果は代表的なサンプルを反映します。この制限は、エンジンが項目ごとの値カウントのインメモリマップを構築するため、Salesforceのヒープメモリオーバーフローを防ぐために存在します。40,000を超える個別の値を持つ項目は、高カーディナリティ項目としてフラグされます。
適用可能な項目タイプ
Section titled “適用可能な項目タイプ”Uniquenessが最も意味を持つのは:
- Email — コンタクト/リードごとに一意であるべき
- Phone — 個人ごとに一意であることが多い
- 外部ID — 定義上一意でなければならない
- テキスト項目 — 名前、説明
あまり意味がないもの:
- Boolean — 2つの値しかない
- Picklist — 設計上限られた値セット
- Date — 多くのレコードが同じ日付を共有する可能性がある
ユースケース
Section titled “ユースケース”- ContactやLeadの重複メールアドレスを検出
- 外部ID項目が本当に一意であることを検証
- 同じ値がレコード間でコピーされるデータ入力の問題を特定
- 重複排除の取り組みを経時的に監視