Uniqueness
Was ist Uniqueness?
Abschnitt betitelt „Was ist Uniqueness?“Uniqueness misst, ob Feldwerte über Datensätze hinweg eindeutig sind. Hohe Uniqueness bedeutet, dass jeder Datensatz einen anderen Wert für das Feld hat — niedrige Uniqueness weist auf Duplikate hin.
Funktionsweise
Abschnitt betitelt „Funktionsweise“Für jedes Feld führt die Uniqueness-Strategie folgende Schritte aus:
- Sammelt alle nicht-null-Werte über Datensätze im Umfang
- Identifiziert doppelte Werte
- Berechnet:
(eindeutige Werte / gesamt befüllte Werte) × 100
Konfiguration
Abschnitt betitelt „Konfiguration“Globale Einstellungen
Abschnitt betitelt „Globale Einstellungen“Der Abschnitt Defaults steuert globale Uniqueness-Optionen:
| Einstellung | Beschreibung |
|---|---|
| Case-sensitive matching | Wenn aktiviert, werden „John Smith” und „john smith” als verschiedene Werte für den Vergleich betrachtet. Wenn deaktiviert, zählen sie als Duplikate. |
| Include blanks in uniqueness checks | Wenn aktiviert, werden leere und null-Werte als eigenständige Werte in den Vergleichsberechnungen behandelt. |
Die Tabelle Field Overrides darunter listet jedes Feld mit seinen aktuellen Einstellungen für Case Sensitive, Include Blanks und Status auf.
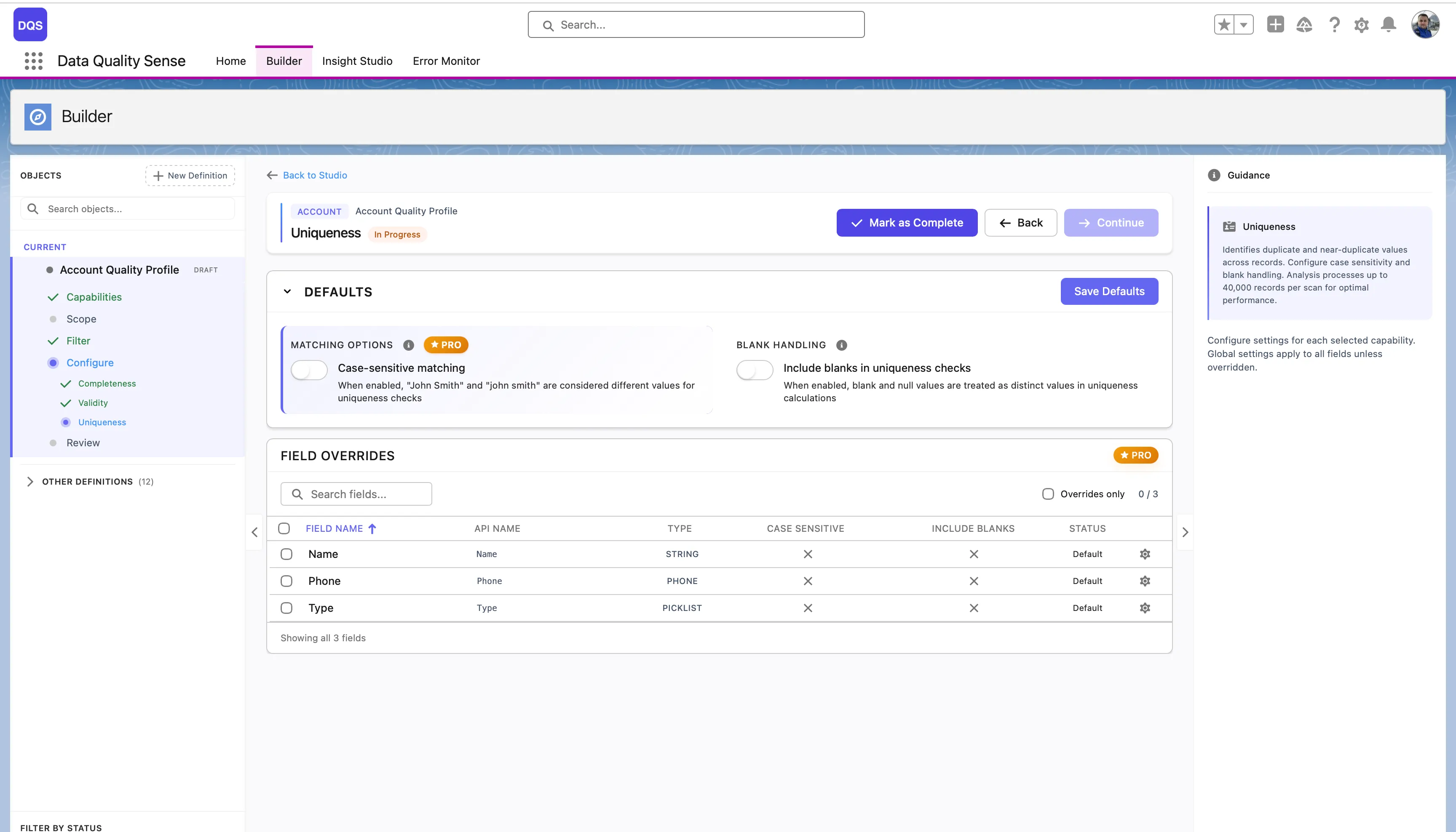
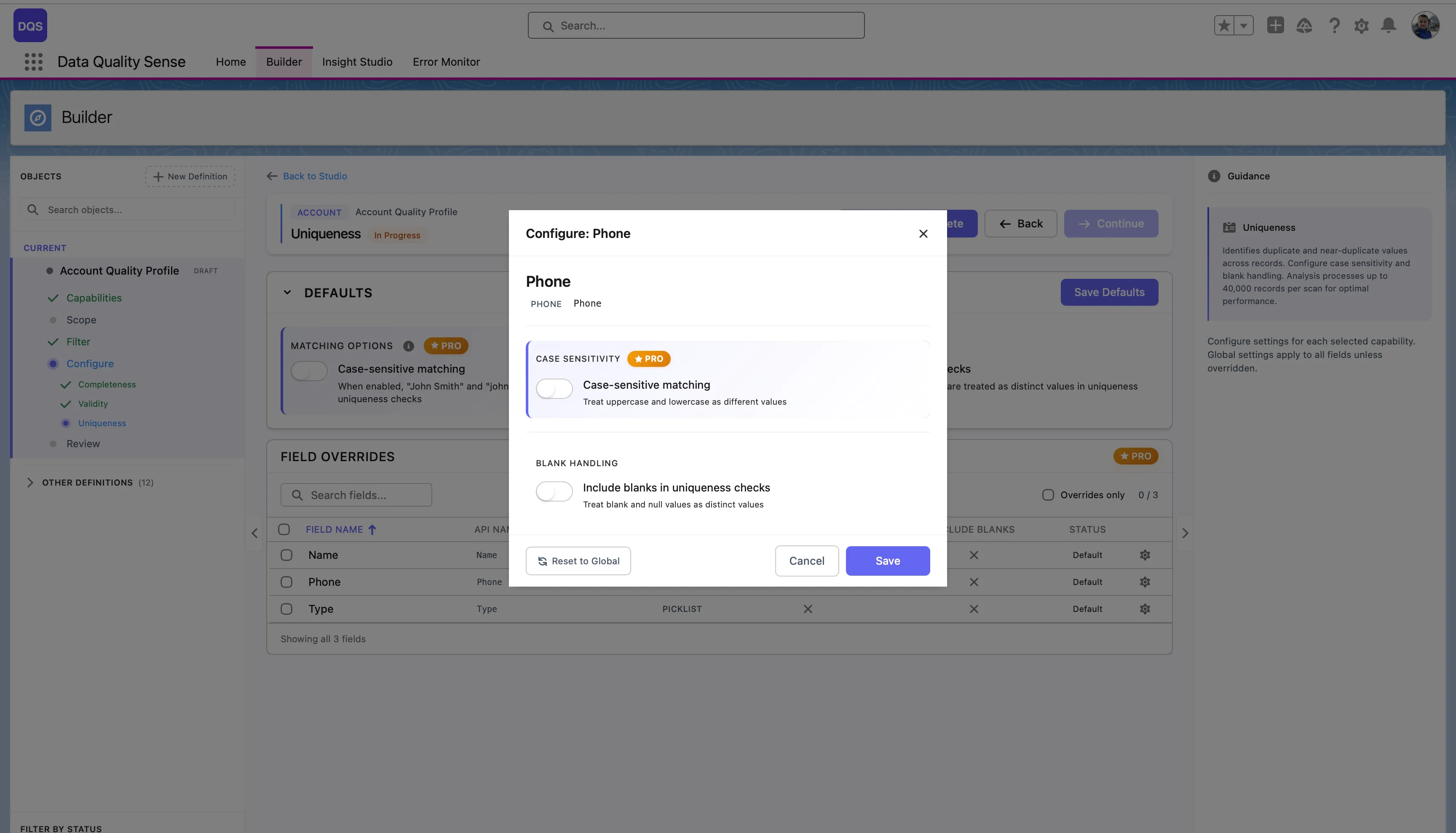
Feldspezifische Überschreibungen
Abschnitt betitelt „Feldspezifische Überschreibungen“Klicken Sie auf ein Feld in der Field Overrides-Tabelle, um dessen Konfigurationsmodal zu öffnen. Sie können Case-sensitive matching und Include blanks in uniqueness checks unabhängig von den globalen Standards umschalten. Verwenden Sie den Link Revert to Global, um das Feld auf die globalen Einstellungen zurückzusetzen.
Bewertung
Abschnitt betitelt „Bewertung“| Ergebnis | Bewertung |
|---|---|
| Alle Werte eindeutig | 100 |
| Einige Duplikate | Proportional zum Prozentsatz eindeutiger Werte |
| Alle Werte identisch | Nahe 0 |
| Keine Daten | 0 |
Analyselimit
Abschnitt betitelt „Analyselimit“Die Uniqueness-Analyse verarbeitet bis zu 40.000 Datensätze pro Scan. Bei Objekten mit mehr Datensätzen spiegeln die Ergebnisse eine repräsentative Stichprobe wider. Dieses Limit existiert, um einen Salesforce Heap-Memory-Overflow zu verhindern, da die Engine eine In-Memory-Map der Wertzählungen pro Feld erstellt. Felder, die 40.000 verschiedene Werte überschreiten, werden als Felder mit hoher Kardinalität markiert.
Anwendbare Feldtypen
Abschnitt betitelt „Anwendbare Feldtypen“Uniqueness ist am aussagekräftigsten für:
- Email — sollte pro Kontakt/Lead eindeutig sein
- Phone — oft eindeutig pro Person
- External IDs — müssen per Definition eindeutig sein
- Textfelder — Namen, Beschreibungen
Weniger aussagekräftig für:
- Boolean — nur zwei mögliche Werte
- Picklist — begrenzte Wertmenge durch Design
- Date — viele Datensätze können Daten teilen
Anwendungsfälle
Abschnitt betitelt „Anwendungsfälle“- Doppelte E-Mail-Adressen über Contacts oder Leads erkennen
- Überprüfen, ob External ID-Felder wirklich eindeutig sind
- Dateneingabeprobleme identifizieren, bei denen derselbe Wert über Datensätze kopiert wird
- Deduplizierungsbemühungen über die Zeit überwachen